Demystifying API Architectures: A Comprehensive Guide
Harnessing the Power of API Architectures: REST, GraphQL, WebSockets, Webhooks, SOAP, gRPC, and MQTT

Im a developer form India currently studying b.tech in CSE from Academy of Technology. I love to explore various tech domain and love the field of web development and Blockchain. I am also an open source enthusiast with several contributions and a open source projects of mine. I love to write technical blogs to share my learnings
In today's interconnected world, Application Programming Interfaces (APIs) play a crucial role in enabling seamless communication and data exchange between various software systems. However, with a multitude of API architectures available, it's important to understand their strengths, weaknesses, and use cases. In this article, we will explore seven popular API architectures: REST, GraphQL, WebSockets, webhooks, SOAP, , gRPC and MQTT along with their key features and real-world applications.
REST (Representational State Transfer):

REST is a widely adopted architectural style for building APIs, focusing on simplicity, scalability, and statelessness. It operates over HTTP and uses standard HTTP methods (GET, POST, PUT, DELETE) to perform operations on resources. REST APIs follow a resource-oriented approach, where each resource is identified by a unique URL (Uniform Resource Locator). This architecture is known for its easy integration, wide compatibility, and caching capabilities, making it suitable for a variety of applications, especially those involving CRUD (Create, Read, Update, Delete) operations.
Here's a small example to illustrate how REST works:
Assuming we have the same blog application with "User" and "Post" entities, a REST API follows a resource-oriented approach where each entity is represented as a unique URL.
To retrieve the username and titles of the posts for a specific user using REST, a client would typically make multiple requests to different endpoints.
First, the client would make a request to retrieve the user's information:
GET /users/123The server responds with the user's details:
{ "id": 123, "username": "john_doe", "email": "john.doe@example.com", ... }Next, the client would make another request to retrieve the posts associated with the user:
GET /users/123/postsThe server responds with an array of posts:
[ { "id": 1, "title": "RESTful APIs 101", ... }, { "id": 2,"title": "Building Scalable Web Applications",...} ]The client receives the responses separately and combines the data as needed.
REST requires multiple requests to retrieve related data. This can lead to over-fetching or under-fetching of data, as the client receives the entire resource representation without the ability to selectively request specific fields.
REST APIs rely on standard HTTP methods to perform operations on resources. For example, creating a new post would involve sending a POST request to the /posts endpoint, updating a post would use a PUT or PATCH request to the /posts/{postId} endpoint, and deleting a post would be done with a DELETE request to the same endpoint.
GraphQL:
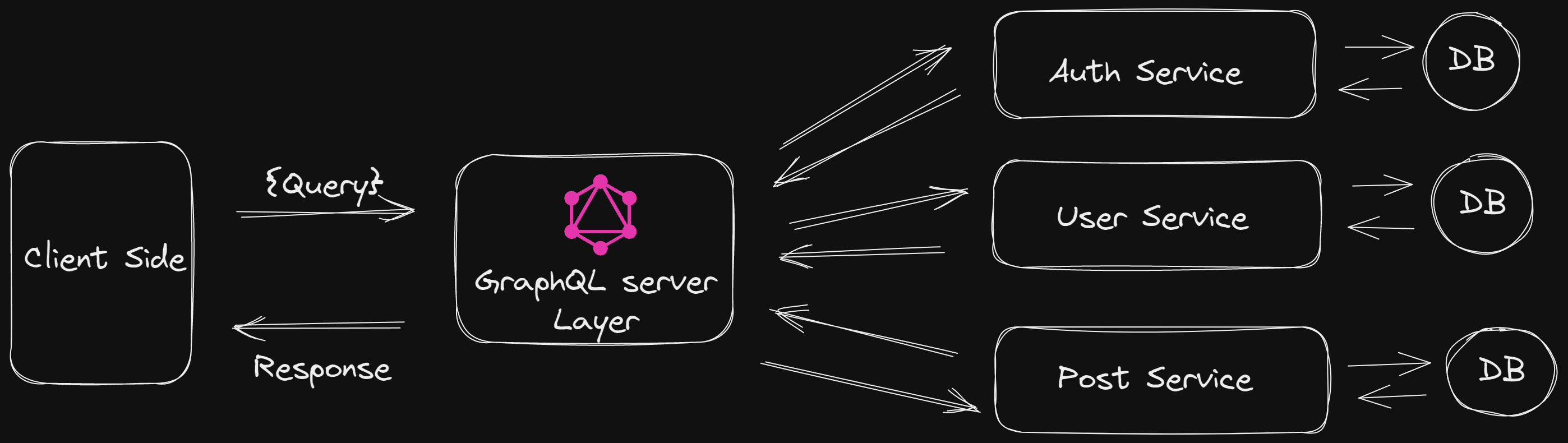
GraphQL is an API query language and runtime that provides a flexible and efficient approach to data fetching and manipulation. Unlike REST, which requires multiple requests to fetch related data, GraphQL enables clients to request precisely the data they need in a single request. It empowers clients to define their data requirements using a declarative syntax, offering increased efficiency and minimizing over-fetching or under-fetching of data. GraphQL is particularly valuable for applications with complex data requirements, mobile applications, and scenarios where bandwidth optimization is crucial.
For Example: Let's assume we have a blog application with two types of entities: "User" and "Post". Each user can have multiple posts associated with them. With a GraphQL API, a client can request specific data from these entities in a single request.
Here's an example GraphQL query that retrieves the username and titles of the posts for a specific user:
query {
user(id: 123) {
username
posts {
title
}
}
}
In this query, the client specifies that they want to retrieve data for a user with an ID of 123. They also specify that they want the username and titles of the posts associated with that user.
The server, which implements the GraphQL API, receives this query and resolves it accordingly. It fetches the requested data from the underlying data source, such as a database. Instead of returning a fixed response structure, GraphQL allows the server to return data in the exact shape requested by the client.
The server processes the query and responds with the requested data in a JSON format:
{
"data": {
"user": {
"username": "john_doe",
"posts": [
{
"title": "GraphQL Introduction"
},
{
"title": "Advanced GraphQL Techniques"
}
]
}
}
}
The client receives the response with the requested data, which includes the username of the user and an array of post titles. This approach eliminates the problem of over-fetching or under-fetching data commonly associated with traditional REST APIs.
With GraphQL, clients have the flexibility to request specific fields, nested relationships, and even perform mutations (updates) or subscriptions (real-time data) within a single query. This reduces the number of round trips between the client and server, improves performance, and allows for efficient data retrieval.
Websockets:
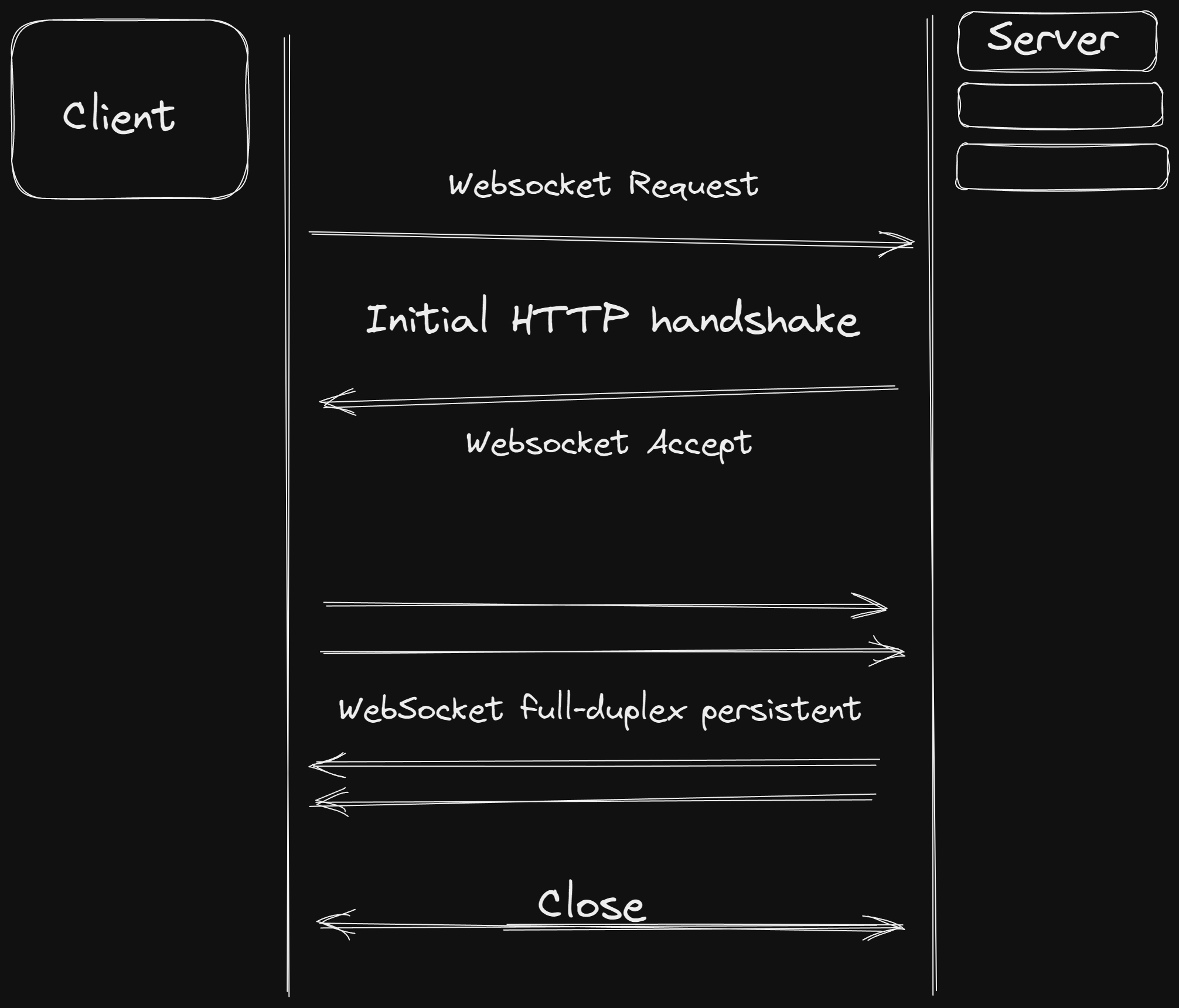
WebSockets introduce a bidirectional, full-duplex communication channel between a client and a server, allowing real-time data streaming. Unlike traditional HTTP-based request-response architectures, WebSockets enable both server and client to initiate data transfer at any time, facilitating instant updates and push notifications. This architecture is well-suited for applications requiring real-time collaboration, chat applications, stock market tickers, and multiplayer gaming.
Example: Assuming we have a real-time chat application where users can send and receive messages. With WebSockets, clients can establish a persistent, bidirectional communication channel with the server, enabling real-time updates.
- Client-Side Connection: The client establishes a WebSocket connection by making a WebSocket handshake request to the server:
GET /chat
Server-Side Connection: The server accepts the WebSocket handshake request and establishes a persistent connection with the client.
Real-time Communication: Once the WebSocket connection is established, both the client and server can send messages to each other at any time, without the need for the client to initiate a request. This enables real-time, bidirectional communication.
For example, when a user sends a message, the client can send a WebSocket message to the server:
SEND: {
"sender": "user123",
"message": "Hello, everyone!"
}
The server receives the WebSocket message and broadcasts it to all connected clients, including the sender. Each connected client receives the message instantly, enabling real-time updates in their chat interface.
Similarly, if another user sends a message, the server broadcasts it to all connected clients, ensuring that all participants receive the message in real-time.
WebSockets are ideal for applications that require instant updates and real-time collaboration, such as chat applications, live notifications, multiplayer gaming, and financial stock tickers.
The WebSocket connection remains open until either the client or the server decides to close it. This allows for ongoing, efficient communication without the overhead of establishing a new connection for each request.
It's important to note that WebSockets are not a replacement for traditional REST or GraphQL APIs but rather complement them by providing real-time capabilities.
Webhooks:
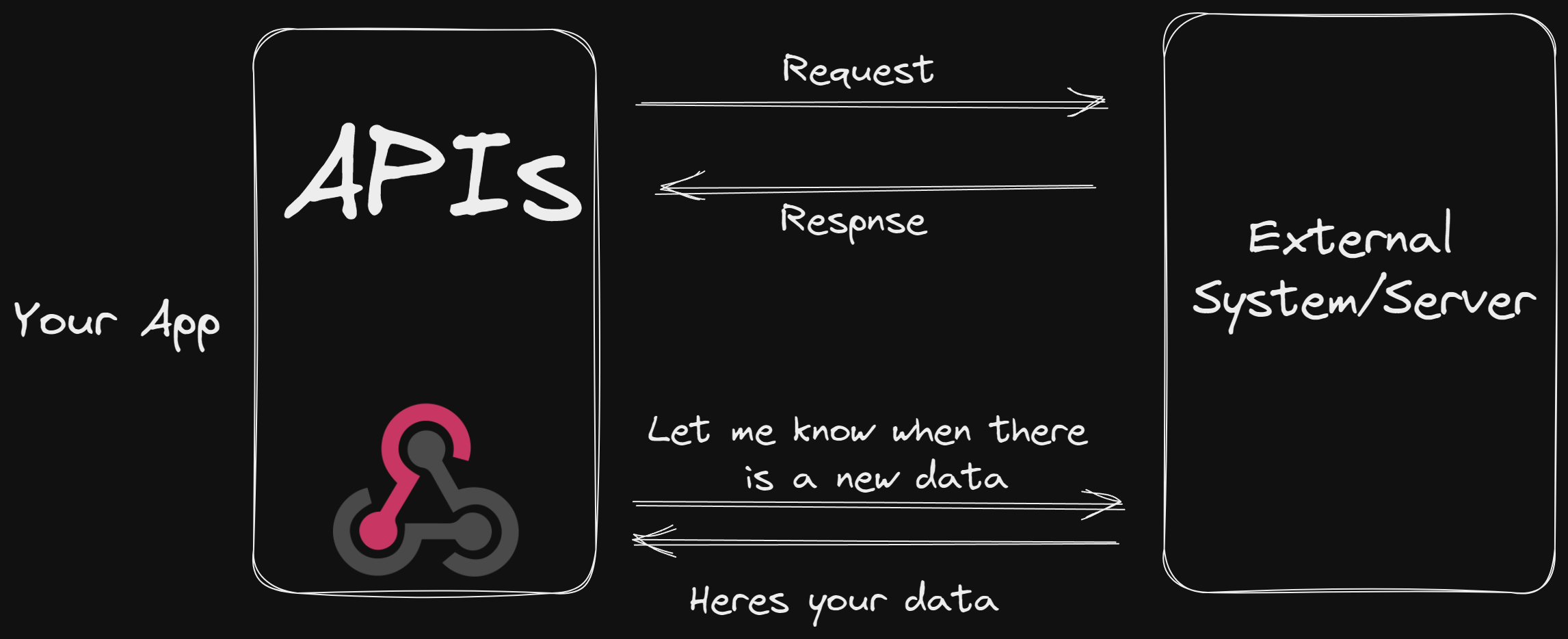
Webhooks are a way for applications to receive automatic notifications or callbacks when a specific event occurs. Instead of regularly polling an API for updates, webhooks allow the API to proactively send data to a predefined URL when an event of interest takes place. Developers can define their own event triggers and specify how the application should respond. Webhooks are commonly used for integrating external services, triggering actions based on events, and building event-driven architectures.
Let's consider a scenario where : we have a subscription service for news articles, and we want to notify subscribers whenever a new article is published.
Subscription Setup: Subscribers provide their callback URL, typically an endpoint on their server, to the news service. This URL will be used for delivering webhook notifications.
Event Trigger: When a new article is published, the news service triggers an event and prepares to send a webhook notification.
Webhook Notification: The news service sends an HTTP POST request to the subscriber's callback URL, containing relevant information about the newly published article. The payload could be in various formats, such as JSON or XML, depending on the agreement between the news service and the subscriber.
POST /webhook/callback Content-Type: application/json { "event": "article.published", "data": { "title": "New Blog Post", "author": "John Doe", "content": "Lorem ipsum dolor sit amet, consectetur adipiscing elit..." } }Subscriber's Server Handling: The subscriber's server receives the webhook notification at the specified endpoint. The server can then process the notification, extract the relevant data, and take appropriate actions, such as updating a local database, sending a notification to subscribed users, or performing any custom logic required.
By using webhooks, the subscriber doesn't need to continuously poll the news service to check for new articles. Instead, the news service proactively pushes the data to the subscriber's server as soon as the event (in this case, a new article being published) occurs.
Webhooks are commonly used for integrating external services, automating workflows, and building event-driven architectures. They provide a way to connect systems and enable real-time updates, reducing the need for constant polling and improving efficiency.
SOAP (Simple Object Access Protocol):
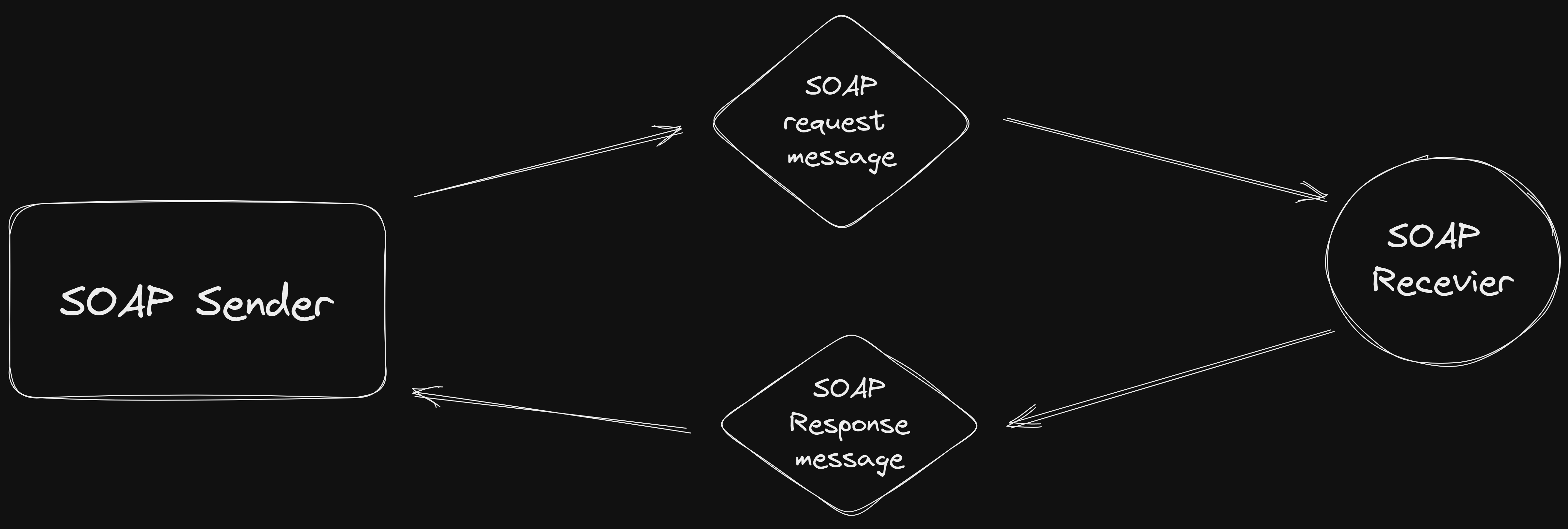
SOAP is a protocol for exchanging structured information over various protocols, including HTTP, SMTP, and more. It uses XML for message formatting and relies on Web Services Description Language (WSDL) to define the API interface. SOAP APIs follow a more rigid approach compared to REST, offering advanced features such as message-level security and transaction management. This architecture is often used in enterprise scenarios, where interoperability, strict data typing, and standardized protocols are crucial.
Let's consider a scenario where we have a SOAP-based weather service that provides weather information based on a specific location.
- SOAP Request Construction: The client constructs a SOAP request, typically an XML document, specifying the required operation and parameters. For example, to retrieve the weather for a specific location, the client would create a SOAP request like this:
<soap:Envelope xmlns:soap="http://www.w3.org/2003/05/soap-envelope">
<soap:Body>
<GetWeatherRequest xmlns="http://example.com/weatherservice">
<Location>London</Location>
</GetWeatherRequest>
</soap:Body>
</soap:Envelope>
SOAP Request Sending: The client sends the SOAP request to the SOAP endpoint URL of the weather service using HTTP or other transport protocols. The request is usually sent as an HTTP POST request, with the SOAP envelope as the request payload.
SOAP Response: The weather service receives the SOAP request, processes it, and generates a SOAP response. The response contains the requested data or the result of the operation.
<soap:Envelope xmlns:soap="http://www.w3.org/2003/05/soap-envelope"> <soap:Body> <GetWeatherResponse xmlns="http://example.com/weatherservice"> <Weather> <Location>London</Location> <Temperature>22°C</Temperature> <Conditions>Sunny</Conditions> </Weather> </GetWeatherResponse> </soap:Body> </soap:Envelope>- SOAP Response Parsing: The client receives the SOAP response and parses it to extract the relevant information. In this case, the response contains the weather details for the requested location.
SOAP provides a standardized way to define the structure of requests and responses using WSDL (Web Services Description Language). WSDL defines the operations, message formats, and available endpoints for a SOAP service, making it easier for clients to understand and interact with the service.
gRPC (Google Remote Procedure Call):
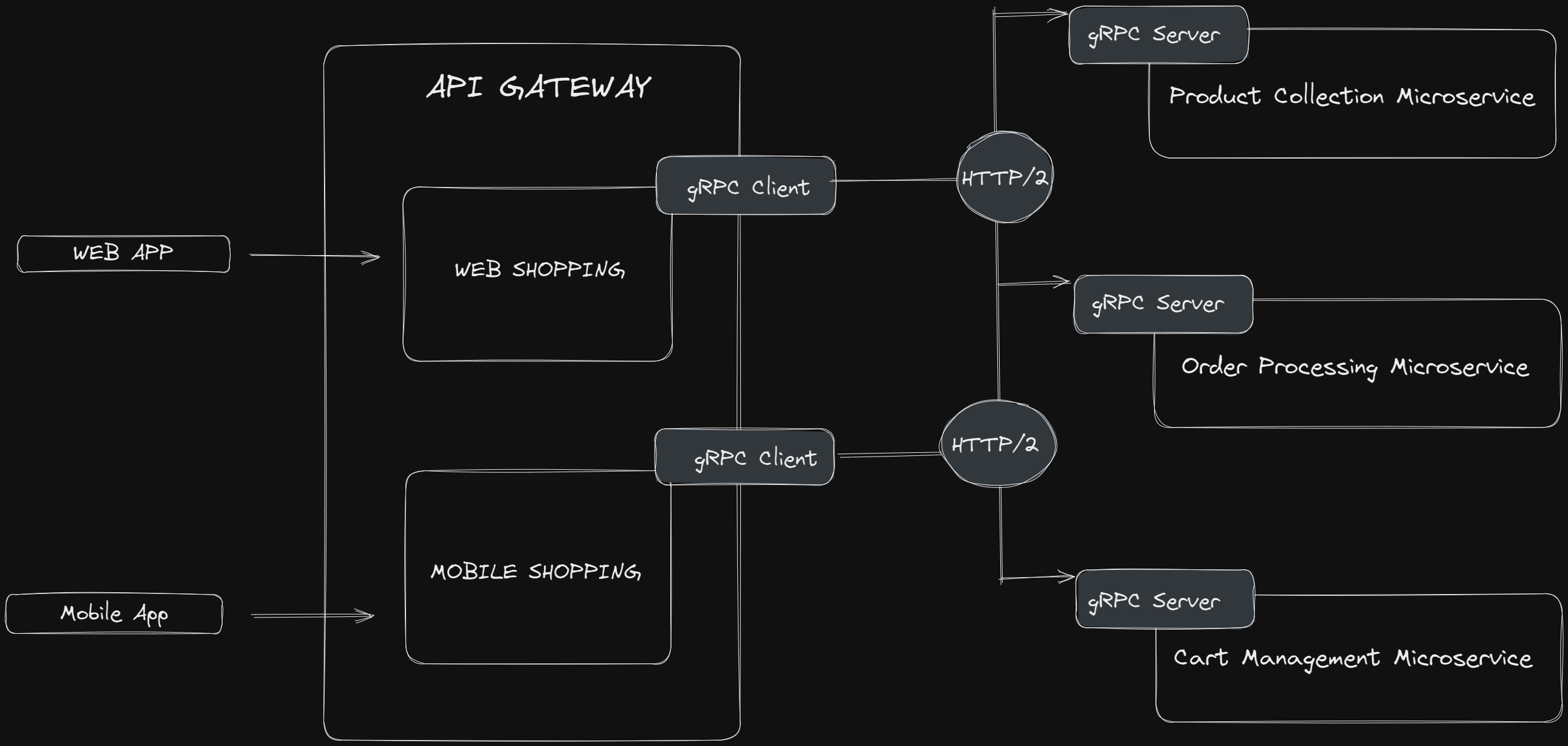
gRPC is a high-performance, open-source remote procedure call (RPC) framework developed by Google. It allows applications written in different languages to communicate seamlessly and efficiently. gRPC uses Protocol Buffers as the interface definition language and operates over HTTP/2, offering bi-directional streaming, flow control, and support for various authentication mechanisms. It excels in scenarios where performance, reliability, and language-agnostic communication are essential, such as microservices architectures, distributed systems, and inter-service communication in cloud-native environments.
Let's consider a scenario where we have a gRPC-based user management service with two operations: "CreateUser" and "GetUser".
Protocol Definition: The service provider defines the service operations and data structures using protocol buffers. The protocol definition specifies the available methods, input parameters, and return types.
syntax = "proto3"; message CreateUserRequest { string name = 1; string email = 2; } message User { string id = 1; string name = 2; string email = 3; } service UserService { rpc CreateUser(CreateUserRequest) returns (User); rpc GetUser(GetUserRequest) returns (User); }Code Generation: Using the protocol definition, code generators create client and server stubs in various programming languages. These stubs provide a simple API that the client and server can use to interact with each other.
Client Request: The client invokes the desired operation by calling the corresponding method on the generated client stub. For example, to create a new user, the client makes the following function call:
user = userServiceStub.CreateUser(CreateUserRequest(name="John Doe", email="john.doe@example.com"))Request Serialization: The gRPC framework serializes the request message, typically in a binary format, according to the specified protocol buffers schema.
Network Communication: The serialized request is sent over the network to the server using HTTP/2 as the underlying transport protocol. gRPC leverages the benefits of HTTP/2, such as multiplexing and header compression, to improve performance and efficiency.
Server Processing: The server receives the request, deserializes it, and invokes the corresponding method on the server stub, passing the deserialized request message as an argument.
Server Response: The server processes the request and generates a response, which is then serialized into a binary format.
Response Deserialization: The serialized response is sent back to the client, where it is deserialized into the corresponding response message.
Client Handling: The client receives the response and can now access the result or data returned by the server. For example, the client can access the user information returned by the "CreateUser" method.
MQTT (MQ Telemetry Transport):
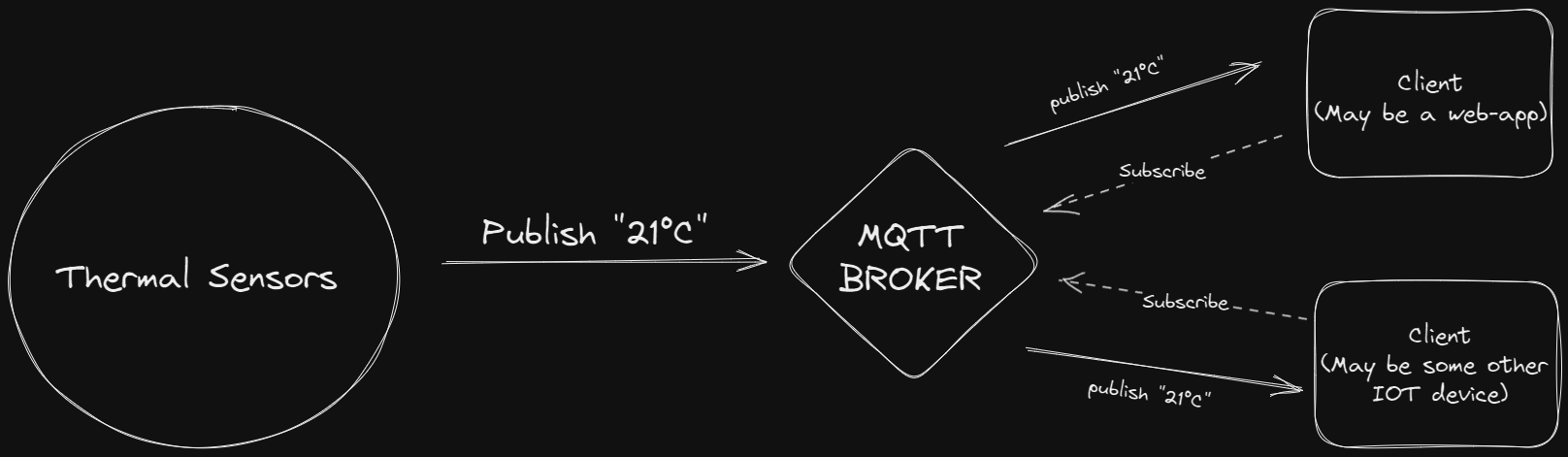
MQTT is a lightweight messaging protocol designed for efficient communication between devices and applications in low-bandwidth, high-latency, or unreliable network conditions. It follows a publish-subscribe messaging pattern, where clients can publish messages to topics or subscribe to topics to receive messages. MQTT is widely used in Internet of Things (IoT) scenarios, where devices with limited resources need to exchange data in a reliable and scalable manner.
Let's consider a scenario where we have a temperature monitoring system that collects temperature readings from various sensors and sends them to a central server using MQTT.
Connection Establishment: The MQTT client, such as a sensor or a device, establishes a connection to an MQTT broker. The broker acts as a central hub for message routing and distribution.
Topic Subscription: The client subscribes to one or more topics of interest. Topics are hierarchical and represent different categories or channels for message distribution. For example, the client could subscribe to the topic "sensors/temperature".
Message Publishing: The client periodically collects temperature readings and publishes them to the MQTT broker, specifying the corresponding topic. The message payload typically contains the temperature value and additional metadata.
Message Distribution: The MQTT broker receives the published message and distributes it to all the clients that have subscribed to the corresponding topic. In this case, all clients subscribed to "sensors/temperature" will receive the temperature readings in real-time.
Message Reception: The clients that subscribed to the topic "sensors/temperature" receive the published messages and can process them accordingly. For example, a client could display the temperature readings on a dashboard or trigger a specific action based on a predefined threshold.
Conclusion:
In this article, we explored six popular API architectures: REST, GraphQL, WebSockets, webhooks, SOAP, and gRPC, along with the MQTT protocol. Each architecture has its own strengths and is suited for different use cases. REST provides simplicity and compatibility, GraphQL offers flexibility in data fetching, WebSockets enable real-time bidirectional communication, webhooks allow event-driven integration, SOAP provides advanced features and interoperability, gRPC excels in performance and language-agnostic communication, and MQTT is ideal for IoT scenarios. Understanding the characteristics and applications of these architectures empowers developers to make informed decisions when designing and implementing APIs for their specific needs. By leveraging the right architecture, organizations can build efficient, scalable, and robust systems that meet the requirements of modern applications.




